Towards a Unified Ruby Model
So I didn't want to write this now, becuase I have a million other things to do, but it seems I have to give up procrastinating on this. Ok. Here's more than you ever wanted to know about ruby, the annotation typesetting paradigm used in East Asia, and it's markup design.
Briefly, ruby text is annotations set within the line spacing above, below, or to the side of the text being annotated. It looks like this:

An example of ruby annotation: the pronunciation of each character in phonetic script over/beside the ideograph.
Ruby in Web technology spans several specifications:
- the original XHTML Ruby Annotation specification, which defines a markup model to handle all levels of ruby, from the simplest to the most complex.
- the current HTML5 Ruby, which defines a different markup model that handles only the simplest ruby structures.
- the current CSS3 Ruby Module, which defines a rendering model for XHTML Ruby Annotation markup, but can't handle HTML5 Ruby and is all kinds of underspecified besides.
Ignoring the current state of the CSS Ruby module for the moment, are several problems with ruby as defined for the Web:
- The designers of XHTML Ruby Annotation didn't understand anonymous box generation, so their markup is excessively verbose.
- The designers of HTML5 Ruby didn't understand the fallback behavior and structural-semantic distinctions XHTML Ruby was designed around, so these requirements were lost in translation.
- Nobody really understands what jukugo ruby is.
About Ruby
Ruby annotation has several use cases:
- Giving phonetic readings for Chinese. Chinese is written entirely in Han ideographs, and in this case, it is very common for every character in the text to be annotated, either in Pinyin (the romanization system used in mainland China) or in Zhuyin Fuhao (a Chinese phonetic script often used in Taiwan).
- Giving phonetic readings for ideographs in Japanese. Japanese is written with a mix of Japanese phonetic scripts and Han ideographs, and in this case only the morphemes expressed in ideographs will be annotated. Sometimes all of them are annotated (as in publications for children), other times only uncommon ideographs or ideographs being used with a nonstandard pronunciation (which is not unusual for proper nouns) are annotated.
- Marking the text with other auxiliary information. This is less common, but the ruby system lends itself particularly well to annotating words or phrases within a text. It can be used to give translations, or originals of translations, expansions of abbreviations, or other kinds of notes.
The purpose of ruby markup is to match up annotations to their base text. In Chinese, understanding how this works is fairly straightforward: there is one syllable of phonetic information per base character, and each syllable is matched to each character. In Japanese, the situation gets more complicated and is, in my experience, poorly understood and not just by Westerners.
Jukugo Ruby
If you look at Japanese ruby cursorily, you will notice that there are two styles of presenting phonetic readings:
- Separating the text over each ideograph, like this:
This style has been called mono ruby because there is one annotation associated to each base character. This is used for words where the pronunciation can be broken down into per-base-character pairings.

Mono ruby: the annotation of each character is aligned over its base character
- Grouping the text together over multiple ideographs, like this:
This style has been called group ruby because the annotation as a group is matched to the base characters as a group. This is used for words where the pronunciation can't be broken down per-base-character. For example, the word "today" is written with the characters 今日, literally "this day". But it's pronounced きょう (kyou), which can't be broken down into a "this" part and a "day" part.

Group ruby: the annotation of a multi-character word is aligned (as a group) over its base characters (as a group)
If you do a little more analysis, however, you'll notice a third pattern:
- Grouping the annotation text together over multiple ideographs
when it's on the same line, but breaking it across lines with a
particular correspondance between the annotation text and the
base text:
In this case the phonetics are placed together over the three kanji because they form one word. But when the word is broken over multiple lines, the phonetics must be kept together with the appropriate base character.
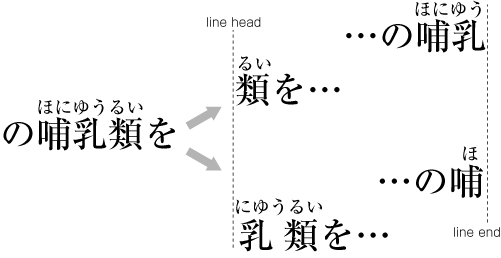
This stylistic pattern is called jukugo ruby, and there have been various proposals on how to mark it up, but many people miss the fundamental issue that distinguishing this from mono ruby is entirely stylistic.

Alternate styles of presenting kana phonetics for 上手, "skill".
In order to render jukugo ruby I need to know both the base-annotation pairing among individual parts of the ruby and also where the word boundaries are. Rendering a word as mono ruby only requires the pairing information; the word boundary information is not used. But whether I render words as jukugo ruby or as mono ruby is a stylistic preference. The markup should thus express both the pairing and the boundary, and there should be a property in CSS that controls whether to render as mono or jukugo ruby.
Fallback
A missing piece of the discussion is fallback and inline rendering of
ruby. Ruby is just an annotation, so while it looks better (and can
visually express more information) to present such annotations as ruby,
parenthesizing the annotation after the base text is also a valid way to
present the same information. For HTML renderers that don't support
ruby, the fallback behavior should lend itself to rendering in this
manner. (This is why the <rp> element was created—to
show parentheses for such down-level clients while hiding the parentheses
for clients that support it.)
In Japanese, such inlining should operate on word boundaries. Even if the ruby is intended to be rendered as mono ruby.
今日(きょう)京都(きょうと)から新幹線(しんかんせん)で東京(とうきょう)に来(き)ました。
None of the proposals for using HTML5 ruby markup for Japanese ruby
address this issue. In fact, they cannot, because HTML5 ruby markup
is not capable of both expressing the base-annotation pairings
within a word and putting the entire annotation of a multi-base
word after the entire base of the word. And here we start to see why
XHTML Ruby Annotation markup was designed the way it was designed: its
markup for multiple ruby pairs within a single <ruby>
seems awkward at first glance because it correctly handles
inlining.
Double Ruby
Sometimes ruby is used on both sides of a base text. XHTML Ruby handles this with dedicated markup. In HTML5 Ruby, it's suggested to nest ruby markup.
Nesting ruby markup works fine for some cases: annotating the Chinese name for San Francisco with both pinyin and the English name, for example. In this case the Chinese (旧金山, i.e. “old gold mountain”) can only be group-related to the English.
<ruby><ruby>旧<rt>jiù</rt>金<rt>jīn</rt>山<rt>shān</rt></ruby><rt>San Francisco</rt></ruby>

But it doesn't work as well when there is more structure than that. For example, if we annotate the Japanese word 上手 (“skill”) with both its kana and romaji phonetics, we have to choose either dropping the information about base-annotation pairings from (at least) one of the annotations, or dropping the word structuring such that neither inlining works correctly nor jukugo ruby is possible.

Alternate styles of presenting both kana and romaji phonetics for 上手, “skill”.
HTML5 option 1: dropping pairing relations in the romaji
<ruby><ruby>上<rt>じょう</rt>手<rt>ず</rt></ruby><rt>jouzu</rt></ruby>
HTML5 option 2: dropping the word relations
<ruby><ruby>上<rt>じょう</rt></ruby><rt>jou</rt></ruby><ruby><ruby>手<rt>ず</rt></ruby><rt>zu</rt></ruby>
My point here isn't that double ruby should be a high-priority item, but
that nesting <ruby> tags is not a correct solution;
it's just a hack.
Anonymous Boxes
Anonymous boxes in CSS are automatically generated boxes that act to make sure the tree structure in the layout engine is coherent. They're a form of automagic that takes incomplete pieces of a complex layout structure such as a table and fills in missing layers. For example, if you put two table cells followed by a table row into a CSS document, CSS will create a two-row table by wrapping the table cells in an anonymous row and wrapping the (now) two consecutive rows in an anonymous table.
XHTML Ruby Annotation did not use anonymous boxes: every bit of layout structure had to be represented as an element. Given that ruby structures can have several layers of hierarchy, this made the syntax extremely verbose.
HTML5 Ruby on the other hand relies heavily on anonymous box generation. It encodes the bare minimum of markup to define the needed structures, and relies on the layout engine to infer the rest.
The anonymous box generation algorithm for ruby is entirely missing from the CSS Ruby spec. But if one were to write it such that it handled HTML5 Ruby, making it handle the equivalent markup in XHTML Ruby Annotation would pretty much just fall out of that: there's just less anonymous boxes to infer. Define an anonymous box generation algorithm that's also compatible with the full XHTML Ruby Annotation spec, and you make possible a whole range of markup between XHTML Ruby Annotation and HTML5 Ruby.
So what might that look like?
Grand Unified Theory of Ruby Markup
Level 1: Simple Ruby
The simple cases can be handled with just an <rt> element.
This structure gives a base-annotation pair:
<ruby><rb>base</rb><rt>note</rt></ruby>
HTML5 allows having multiple ruby pairs within the same
<ruby> tag, which uses much less markup.
It would be handy for marking up an entire paragraph of
Chinese with phonetics:
<ruby>base1<rt>note1</rt>base2<rt>note2</rt></ruby>
Level 2: Multi-pair Word Ruby
By adding back the <rb> element, we can express
both of the required relations for jukugo ruby as well as handle
inlining correctly:
<ruby><rb>base1</rb><rb>base2</rb><rt>note1</rt><rt>note2</rt></ruby>
This pattern can be mixed with other (simple and/or multi-pair) ruby
inside a <ruby> element as well.
Level 3: Double Ruby
By adding back the <rtc> element to separate
levels of annotation, we can express double ruby:
<ruby>base<rt>note1</rt><rtc>note2</rtc></ruby>
This pattern can also express a second level on multi-pair word ruby:
<ruby><rb>base1</rb><rb>base2</rb><rt>note1</rt><rt>note2</rt><rtc><rt>NOTE1</rt><rt>NOTE2</rt></rtc></ruby>
By defining <rtc> content that's not inside
an <rt> to span all the bases (rather than,
e.g. just the first one), we can also handle the group-over-multi-pair
pattern (the San Francisco example above):
<ruby><rb>base1</rb><rb>base2</rb><rt>note1</rt><rt>note2</rt><rtc>spanning note</rtc></ruby>
Level 4: Full Complex Ruby
XHTML Ruby Annotation can handle more esoteric and complicated ruby
structures using a rbspan attribute. I don't remember anyone
asking for this in the requirements discussions I attended in Tokyo and
Taipei (whereas I do remember requests for jukugo ruby and double ruby),
but if it becomes important in the future, adding an rbspan
attribute to Level 3 markup would get us there.
Markup Model
Putting all this together (and including the <rp>
element), we get the following content models:
<ruby>- A
<ruby>element can contain phrase content,<rb>elements,<rt>elements,<rp>, and<rtc>elements. <rb>- An
<rb>element can contain phrase content, but cannot contain<rb>,<rt>,<rp>, or<rtc>elements. <rt>- An
<rt>element can contain phrase content, but cannot contain<rb>,<rt>,<rp>, or<rtc>elements. <rp>- An
<rp>element can contain phrase content, but cannot contain<rb>,<rt>,<rp>, or<rtc>elements. <rtc>- An
<rtc>element can contain<rp>and either phrase content or<rt>elements, but cannot contain<rb>or<rtc>elements.
XHTML Ruby Annotation also has an <rbc> element,
but I don't really see a need for it; it doesn't disambiguate anything,
and CSS can easily infer a box around consecutive ruby bases. But it
could be added for compatibility, and allowed to contain
<rb> elements.
Optimizing Ruby Parsing
HTML has a number of shorthand tricks it can play to reduce the amount of typing in creating a markup document. One of the main ones is dropping end tags where they can be inferred by context. (Another less obvious one is inferring start tags.)
If I were designing ruby HTML parsing from scratch, I would consider
making the end tags of the <rb>, <rt>,
<rp>, and <rtc> elements all optional.
This would mean
<rb>auto-closes<rb>,<rt>,<rp>, and<rtc><rt>auto-closes<rb>,<rt>, and<rp><rp>auto-closes<rb>,<rt>, and<rp><rtc>auto-closes<rb>,<rt>,<rp>, and<rtc></ruby>auto-closes<rb>,<rt>,<rp>, and<rtc>
This would shorten the examples from the section above to:
- Level 1: Simple Ruby
<ruby>base<rt>note</ruby>- Level 2: Multi-pair Word Ruby
<ruby><rb>base1<rb>base2<rt>note2<rt>note1</ruby>- Level 3: Double Ruby
<ruby>base<rt>note1<rtc>note2</ruby><ruby><rb>base1<rb>base2<rt>note1<rt>note2<rtc><rt>NOTE1<rt>NOTE2</ruby><ruby><rb>base1<rb>base2<rt>note1<rt>note2<rtc>spanning note</ruby>
Infer the <ruby> start tag, and you can shorten
things even more:
- Level 1: Simple Ruby
<rb>base<rt>note</ruby>- Level 2: Multi-pair Word Ruby
<rb>base1<rb>base2<rt>note2<rt>note1</ruby>- Level 3: Double Ruby
<rb>base<rt>note1<rtc>note2</ruby><rb>base1<rb>base2<rt>note1<rt>note2<rtc><rt>NOTE1<rt>NOTE2</ruby><rb>base1<rb>base2<rt>note1<rt>note2<rtc>spanning note</ruby>
Conclusion
Well, that's it for the braindump. I look forward to working on the CSS Ruby spec in the future, and I hope to see some improvements to HTML Ruby as well.